AWS ALB returns 503 for Istio enabled pods
Deploying a service mesh solution like Istio in the Kubernetes cluster brings many benefits, however it increases the complexity of the entire setup and makes troubleshooting of potential issues more difficult than before. One of the most common problems people experience after adding an Istio sidecar to the cluster are 5xx errors. I can’t count the amount of different articles, blog posts or github issues flying around that tries to address 500 errors with Istio. The point is that there is no silver bullet to eliminate those errors, as different scenarios require different mitigation techniques. This article will cover one of the issues we experience for services that were Istio sidecar enabled and were exposed directly via AWS Application Load Balancer.
TL;DR;
Even if Istio documentation doesn’t mention that istio ingress gateway is a mandatory component in the mesh, I highly recommend to add it if you use AWS load balancer controller. AWS ALB is a component that resides outside of the Kubernetes cluster and doesn’t follow the state of the pods — it continues to send a traffic to a istio-proxy sidecar even if the pod gets into “Terminating” state. As a result 503 errors can be observed.
SETUP
Before I describe what the issue was, let’s take a look at the following diagram to understand the testing scenario. We used “echo” application which is just a silly http service. The deployment of an “echo” contains 2 replicas and a service of NodePort type. To expose the service we used AWS load balancer controller.

Istio service mesh contains various components, Istio Ingress Gateway being one of them. Nevertheless it’s not included in the presented scenario, so let me elaborate on why this piece of the puzzle is missing.
First of all, Istio ingress gateway is not a mandatory component and non of the Istio best practices documentation clearly says it should be used to forward ingress traffic. Yes, it would bring all the cool features of Istio at the edge of your cluster, but it’s not mandatory to install it.
Secondly, migrating to the Istio service mesh is a complex process which should be approached on a step by step basis. It’s much easier to enable Istio sidecar for the given pods as the first migration step, and then switch the traffic to the Istio ingress gateway at the next phase. And this is exactly the moment when you may encounter the issues.
Into the details
HTTP connection flow
Let’s take a look at a diagram presenting how HTTP connection works in the described setup.
Using plain HTTP instead of HTTPS between ALB and k8s pods is definitely not the best practice, however I used it for the purposes of this article, as it helps to demonstrate the whole concept.

As AWS ALB is a Layer 7 proxy, it terminates a HTTP request to perform various operations like a TLS certificate validation, adding custom headers (e.g. x-forwarded-for) and route traffic to an appropriate destination. Once HTTP request from a client is processed, ALB establishes upstream TCP connection to forward traffic towards the destination. My point is to highlight the fact that HTTP session between a client and ALB is independent from the connection established between ALB and a k8s pod.
When Istio sidecar is enabled, it modifies iptables rules of the k8s node in such a way that traffic addressed to the application container is intercepted by Istio, also Istio runs Envoy in the background which is another Layer 7 proxy so TCP connection between ALB and Envoy is established. The last step is to establish connectivity between Envoy and the application that runs in the main container of the pod — in our case an “echo” app.
As a result when client sends a HTTP request, 3 separate connections are established (each of them marked with a different color on the diagram above)— one between a user and ALB, second between ALB and the sidecar (Envoy proxy) and last between sidecar and application running in the main container.
Reveal the issue
To be able to simulate user traffic and visualize the problem I used Locust. I started the stress tests and restarted the deployment (containing 2 pods) of an echo app. The results are presented below.

503 errors start to occur exactly when I restarted the deployment. The first thought I had was to double check if an “echo” app performs a graceful shutdown on receiving the SIGTERM- it did. Next, I decided to verify if Istio is the component responsible for that unexpected behaviour. The test couldn’t be any simpler — I disabled the Istio sidecar on an echo app and run Locust test one more time.
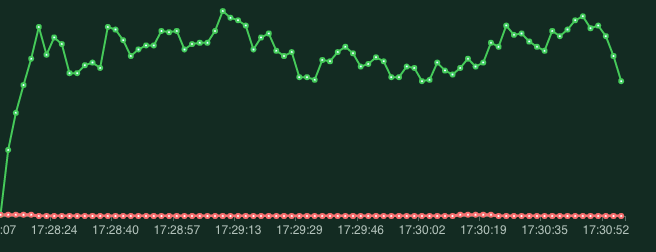
This time no 503 errors. So why does the Istio break the connection between client and application during the deployment process?
Pod termination process
A prerequisite to understand the issue is to know exactly what happens when a pod is being terminated during the redeployment process. This great article from google explains it in more details. As you can see the first step of a termination process is to exclude the terminating pod from the endpoint list of the corresponding service, so no traffic is redirected to that pod any more. If this is true, why can we see such a high number of 503 errors when the pod is being deleted? Why are the requests from ALB being redirected by the k8s nodes to the pod that is in a termination state?
HTTP Connection persistence
If we would go back to early ages of HTTP 1.0 adoption, the process of sending and receiving the HTTP would look like the following:
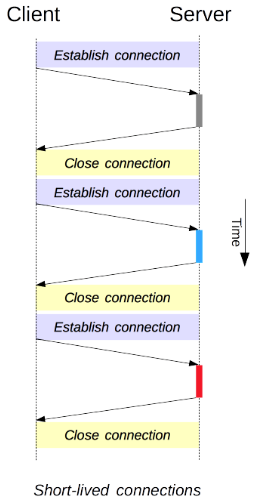
Every HTTP session would have its own TCP connection — once the HTTP response is delivered the TCP connection is closed. Another HTTP request opens a new TCP connection and so on and so forth.
If that’s the case, then in our scenario every request from the user would establish a new TCP session to ALB, then load balancer would open a new TCP session to the Istio proxy and finally, Istio would establish a session with an echo app so the HTTP request is delivered. In that sequence of events there is no room for 503 errors, because when ALB tries to open a new TCP session, traffic gets redirected by k8s nodes only to the healthy echo pods — terminating pod is not on the endpoint list so it can’t participate in the selection process of the destination target.
But things have changed since HTTP 1.0.
HTTP 1.1 introduced the concept of connection persistence, which is the default in this HTTP standard. What it means is that the source and the destination establish a TCP connection upon sending a HTTP request. After a HTTP response is delivered to the source, the connection is kept open waiting for more HTTP traffic. The connection is closed once there is no more HTTP traffic and an idle time expiries. An idle time varies between different implementations e.g. Envoy uses 60min for TCP idle timeout as the default.
This mechanism increases the performance by eliminating the need of establishing and tearing down the TCP connection for every single HTTP request.
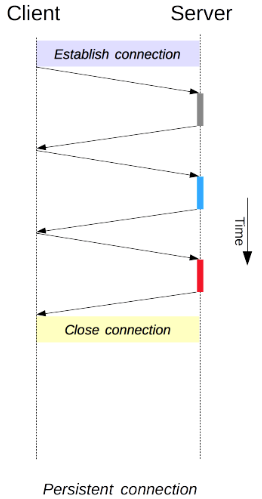
In fact, multiple TCP connections between source and destination can be opened at the same time, creating a so called “connection pool”. Consider the diagram below to see how a TCP connection pool may look like in our scenario:
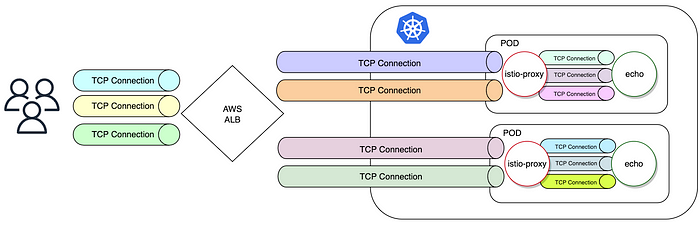
Different colours of TCP pipes suggest that all the TCP connections between client and ALB, ALB and Envoy, Envoy and an application are independent of each other. Those connections are established and kept open to be reused for next HTTP session.
In our scenario, when a new HTTP request arrives to an ALB, and the TCP connection from an ALB to istio-proxy sidecar is already present, the process of selecting a healthy pod from the endpoint list of particular services doesn’t occur — the connection is already there and will be used to forward the HTTP traffic. Selecting the pod / endpoint happens only during the establishing of a new TCP connection.
If the above is true, then regardless whether an Istio is in use or not, how can any HTTP application perform a graceful termination process while TCP connections from the clients are open and the HTTP traffic is constantly flowing?
Stopping any HTTP service requires the mechanism which tells the other side of the wire that it should close all the TCP connections and establish the new ones if needed, as the service will stop operating very soon.
Graceful shutdown and HTTP Connection: Close
What graceful shutdown of a web application does, amongst others things, is to leverage the “HTTP Connection: Close” header to notify the client that the TCP connection will be terminated. This forces the client to establish a new connection. Establishing a totally new end to end TCP connection would solve our problem, if an AWS ALB established a new connection to an echo pod for the first request that arrives from the client to ALB after the pod started the termination process, it wouldn’t hit the terminating pod as it wasn’t on the kubernetes endpoint list any more. However, in our case, sending the “HTTP Connection: Close” header by an echo app doesn’t necessarily mean the user or ALB closes the connection to the pod that the message originated from. The HTTP standard defines a concept of hop-by-hop headers explained in this article. The “Connection” header is treated as a hop-by-hop header which means that the Layer 7 proxy won’t propagate this header downstream. This is at least how the Envoy behaves — see corresponding discussion on github.
This explains why the setup without Istio sidecar works as expected — the pod goes into the termination state and the pod is removed from the endpoint list, then the application running in the container starts to send the “Connection: Close” HTTP headers that reaches AWS ALB. The load balancer closes all the connections that it gets “Connection: Close” for and it starts to establish new connections. As a result the new TCP connection is forwarded to another, healthy pod which is present on the k8s endpoint list — this way the user won’t see any 503 errors on his side.
When Istio sidecar is added to the picture, an application sending the “HTTP Connection: Close” headers reaches the Envoy first. At this stage Envoy will start the termination of the TCP connection between itself and the application, however it won’t pass the “Connection: Close” further to AWS ALB. As a result the connection between AWS ALB and the Envoy remains open and the HTTP requests from the user arrives to the ALB, eventually reaching the Istio sidecar proxy of a terminating pod. At this stage the connections between application and Envoy are being terminated and Envoy can’t establish new TCP connections to the echo app (graceful shutdown of the web application disables the ability to accept any new connections). As the traffic can’t reach the main container, an Envoy returns a 503 to the ALB and that’s how the end user sees the errors.
Once the application finishes sending the “HTTP Connection: Close” and terminates all the TCP connections to an Envoy, Istio sidecar starts its own graceful shutdown process (holding off termination of istio sidecar is not the default setting of the Istio mesh— see the “Bonus section” at the end of the article to get more details about this). At this stage Istio sidecar terminates all the connections to the ALB, once this is completed, ALB must establish new connections to the echo service whilst selecting only the healthy pods. When all the connections between ALB and an Istio sidecar are terminated, the client stops getting 503 errors and the traffic is back to normal.
SOLUTION
The problem may be solved by hiding an application behind the Istio Ingress Gateway. The Istio Ingress Gateway is a set of additional Envoy proxies deployed in their own pods, that accept the traffic from AWS ALB. The diagram below represents the setup with Istio ingress gateways in use.
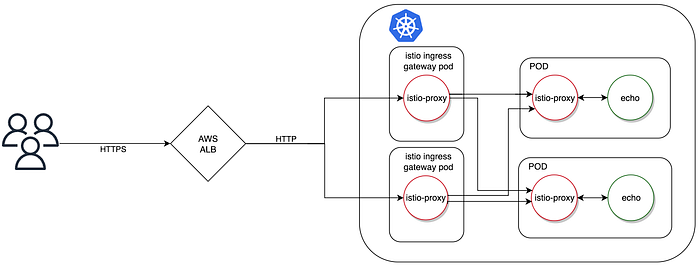
The key to see how this helps to solve the issue is to understand how an Envoy processes each HTTP request it receives. You may find the detailed description in Envoy docs, however the key takeaway is highlighted below:
The most important HTTP filter is the router filter which sits at the end of the HTTP filter chain. When
decodeHeadersis invoked on the router filter, the route is selected and a cluster is picked. The request headers on the stream are forwarded to an upstream endpoint in that cluster. The router filter obtains an HTTP connection pool from the cluster manager for the matched cluster to do this.Cluster specific load balancing is performed to find an endpoint. The cluster’s circuit breakers are checked to determine if a new stream is allowed. A new connection to the endpoint is created if the endpoint’s connection pool is empty or lacks capacity.
In other words, when a HTTP request is sent by the ALB and received by an Envoy (ingress gateway), at the end of the packet processing, Envoy will check the list of the endpoints that it can forward the request to. This is the key difference between the ALB sending a HTTP request to the pod and the Envoy (ingress gateway) sending the same request. An Envoy is a component that sits in the k8s cluster and it constantly tracks the list of the endpoints for each service. The moment when a pod enters a termination state and is removed from the k8s endpoint list, the Envoy removes it from its list of endpoints as well. And remember, this happens before the application goes into a graceful shutdown. As a result, the first HTTP request that arrives to the Istio Ingress Gateway after the application pod starts its termination process, is redirected to the healthy pods that belong to the service of our application, resulting in a lack of 503 errors.
Istio Ingress Gateway termination
The obvious question that comes to a mind is:
“Doesn’t the presented solution shift the issue from an application pod to the ingress gateway pod and what will happen during the deployment of Istio Ingress Gateway?”
The “Bonus section” at the end of this article explains why the Istio acting as a sidecar should hold off its own graceful shutdown until the main container exits properly. But with an Istio Ingress Gateway this is not the case — there is no sidecar. Envoy is a main container and doesn’t need to wait for the other containers to exit. Upon receiving the SIGTERM it immediately starts the graceful shutdown, closing the upstream and downstream connections at the same time. Since the TCP connections to the ALB got terminated, the ALB must use the connection pool to the healthy pods or establish a new connection upon receiving HTTP traffic from the user. Doing so is only possible with the pods available on the k8s endpoint list and at this point the terminating Istio ingress pod is not there anymore.
To sum up, even if the Istio Ingress Gateway is not a mandatory component in the Istio service mesh, I would highly recommend to use it if any HTTP proxy is deployed in front of the Kubernetes cluster.
Bonus section
Why does the Istio sidecar hold off its graceful shutdown?
When a pod is getting terminated, all the containers running in a pod gets a SIGTERM a the same time. If an Istio sidecar is enabled on the pod this behavior may be another root cause of the errors. If an Envoy exits before the application container, the application may not finish sending HTTP responses or some other in-progress operations as expected. That’s why it’s important to force Istio to wait until an application container in the pod finishes its graceful shutdown first. A full description of this scenario and its possible solutions is beyond the scope of this article. To read more about Istio termination order, follow this github discussion.
